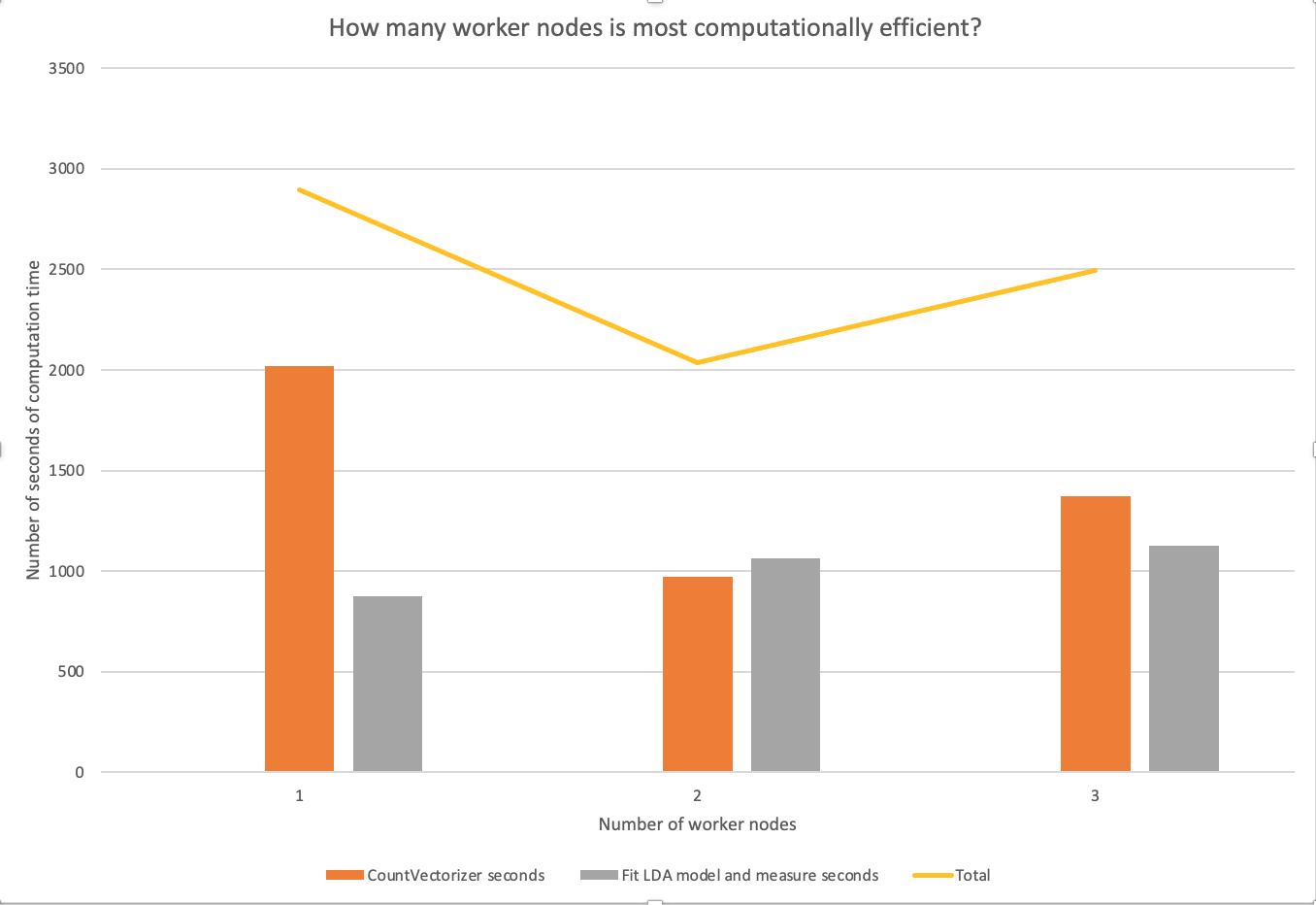
Topic Modelling of UK Parliamentary Speeches Using Spark¶
Abstract¶
The goal of this project is to investigate the use of Spark machine learning algorithms to perform clustering and topic modelling of a new gathered dataset containing speeches by Members of Parliament of the UK House of Commons over the course of the past year. The aim is to determine the best approach for modelling this data and how to best harness the distributed computing power of Spark to do this with computational efficiency. This text data is very high-dimensional so the algorithms can become very computationally expensive without efficient systems. I will also discuss validating the topic model and visualizing the results.
Table of Contents¶
- Introduction
- The Data
- Computing Set-up
- Summary of Data
- Modelling
- Computational Efficiency
- Conclusion
- References
1. Introduction¶
Apache Spark¶
Apache Spark is a unified analytics engine for large-scale distributed data processing. It was designed by researchers at UC Berkeley beginning in 2009 in an effort to improve the existing MapReduce technology. They were aimiming to make it both more efficient for interactive for iterative computing jobs, as well as to make it a less difficult system to learn. Spark provides in-memory storage for intermediate computations, making it much faster than Hadoop MapReduce. It incorporates libraries with composable APIs for machine learning (MLlib), SQL for interactive queries (Spark SQL), stream processing (Structured Streaming) for interacting with real-time data, and graph processing (GraphX). In this paper I will be making use of Resilient Distributed Datasets (below), Spark DataFrames, the Spark SQL API and I will be relying on MLlib implementation of machine learning algorithms to build a Latent Dirichlet Allocation (LDA) topic model.
Resilient Distributed Datasets (RDDs) and DataFrames¶
An RDD is an immutable distributed collection of elements of data, partitioned across nodes in a cluster that can be operated in parallel with a low-level API that offers transformations and actions. RDDs are extremely useful in many of the processing steps of this paper and Spark makes it very easy to move your data between RDDs and DataFrames, with simple API method calls, depending on which format better suits your needs.
In general, I will be using RDDs in the processing steps when I need to do iterative operations on the data in a distributed way and I do not need the structure of a DataFrame. I will then transition to using DataFrames, which allows me to impose structure onto the data including useful functionality like column names.
Topic Modelling Background¶
Topic models offer an automated procedure for discovering the main "themes" in an unstructured corpus of texts. This is a form of unsupervised machine learning because the topic model requires no labelled data. The model determines themes from a set of documents using a probabilistic model based on word frequencies and creates document clusters based on the breakdown of the themes within the documents.
The topic model I will be using is called a Latent Dirichlet Allocation. This is a "mixture model" meaning that documents can contain multiple topics and words can belong to multiple topics.
Latent Dirichlet Allocation¶
From: Probabilistic topic models, David Blei, 2012.
The Latent Dirichlet Allocation topic model assumes a statistical model that generated the observed corpus and then estimates the model in order to recover latent topics under the assumptions made. Each document is assumed to contain weights of topics and each topic is assumed to contain weights of words.
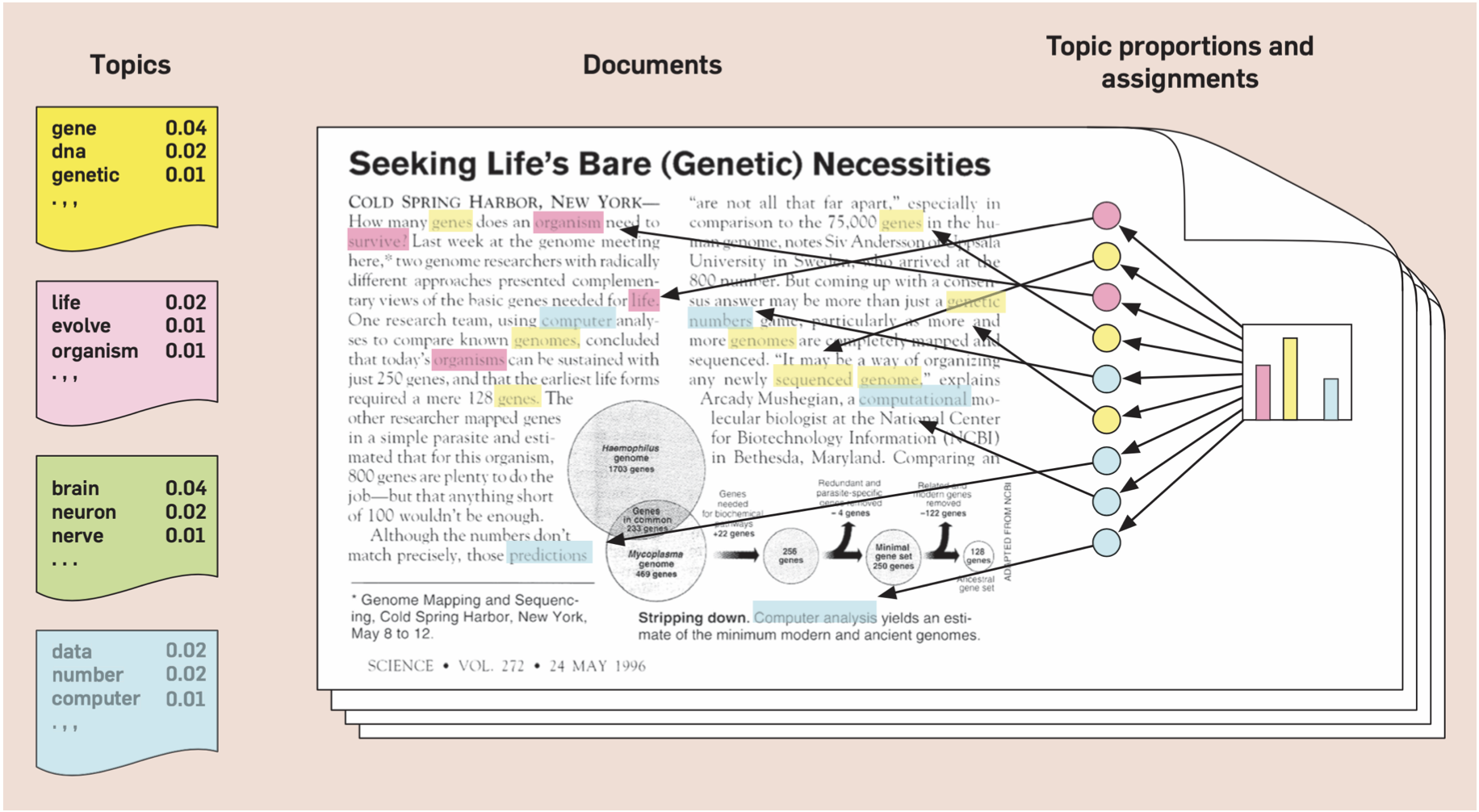
The Latent Dirichlet Allocation makes use of a probability distribution called the Dirichlet distribution.
Dirichlet distribution: probability distribution over a simplex¶
From: Wikipedia.
The LDA model assumes that the documents have been generated using a generative model. For each document its topic shares are drawn from a Dirichlet distribution to determine the topic distributions for the given topic. Then it is possible to draw word shares from a second Dirichlet distribution for each of the topics in the document. Finally, the model fills in each document with words by drawing a topic from the given document's multinomial topic distribution and drawing a word by taking a draw from the corresponding multinomial topic distribution. Of course, this is not how Parliamentary speeches (or any documents written by humans) are actually written, but assuming that this is how they are generated allows us to back out the shares of topics within documents and the shares of words within topics.
These successive draws can also be visualized using plate notation as in Blei, 2012. In the diagram below $\alpha$ represents the topic distribution and $\eta$ represents the word distributions.
Plate Notation¶
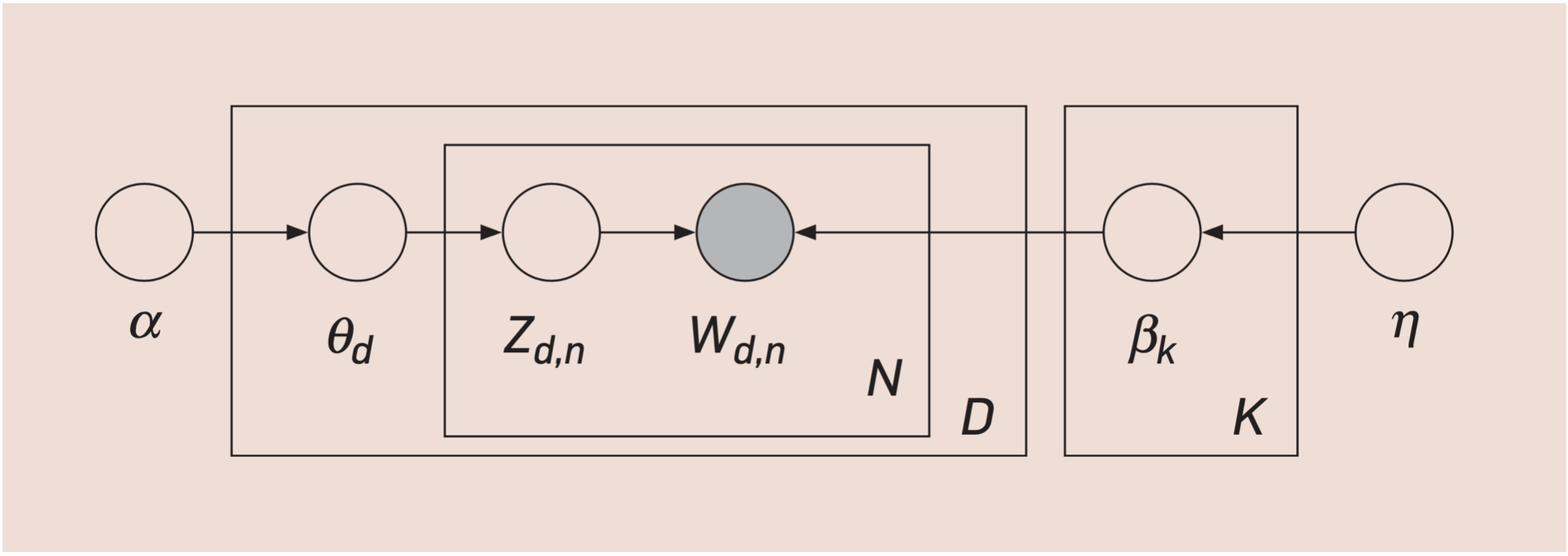
From: Probabilistic topic models, David Blei, 2012.
Estimating the topic model is done in a Bayesian framework. The two Dirichlet distributions from which we have drawn our topic shares and our word shares are the prior distributions. Using Bayes' rule, and our actual text data, we can update the prior distributions to obtain new posterior distributions of the topics and words. Once we have these distributions we can form clusters by grouping documents together based on their similarities in terms of topic distribution. These clusters are the objective of this kind of model and of this paper.